分布式理论
date
icon
password
Sub-item
Blocked by
Parent item
type
status
slug
summary
tags
category
Blocking
📎 Reference
欢迎补充
Reference
(https://cloud.tencent.com/developer/article/1583185)
并行方式
数据并行
模型并行
模型载入后,在每个gpu上都有一个副本,通过将数据分组给每个gpu的方式进行前向计算
同步更新
每个batch,等所有gpu都计算好梯度,然后收集它们的梯度然后取均值之后,统一进行参数的更新。
但问题在于,每次更新梯度,都得等最慢的一张卡,相当于木桶原理,比较浪费其他卡的性能(特别是不同型号卡一起的情况下)
那这个时候,是又哪一块gpu主导更新呢?是每一块卡都拿到
异步更新
异步训练中,各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数,这样总体会训练速度会快很多。但是异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数其实已经被其它设备更新过了,此时这个梯度就过期了,因为现在的模型参数和训练前采用的参数是不一样的。由于梯度失效问题,异步训练虽然速度快,但是可能陷入次优解(sub-optimal training performance)
为什么是【可能发现模型参数其实已经被其它设备更新过了】,既然是异步,那就一定有先后,这是必然的吧
分布式架构
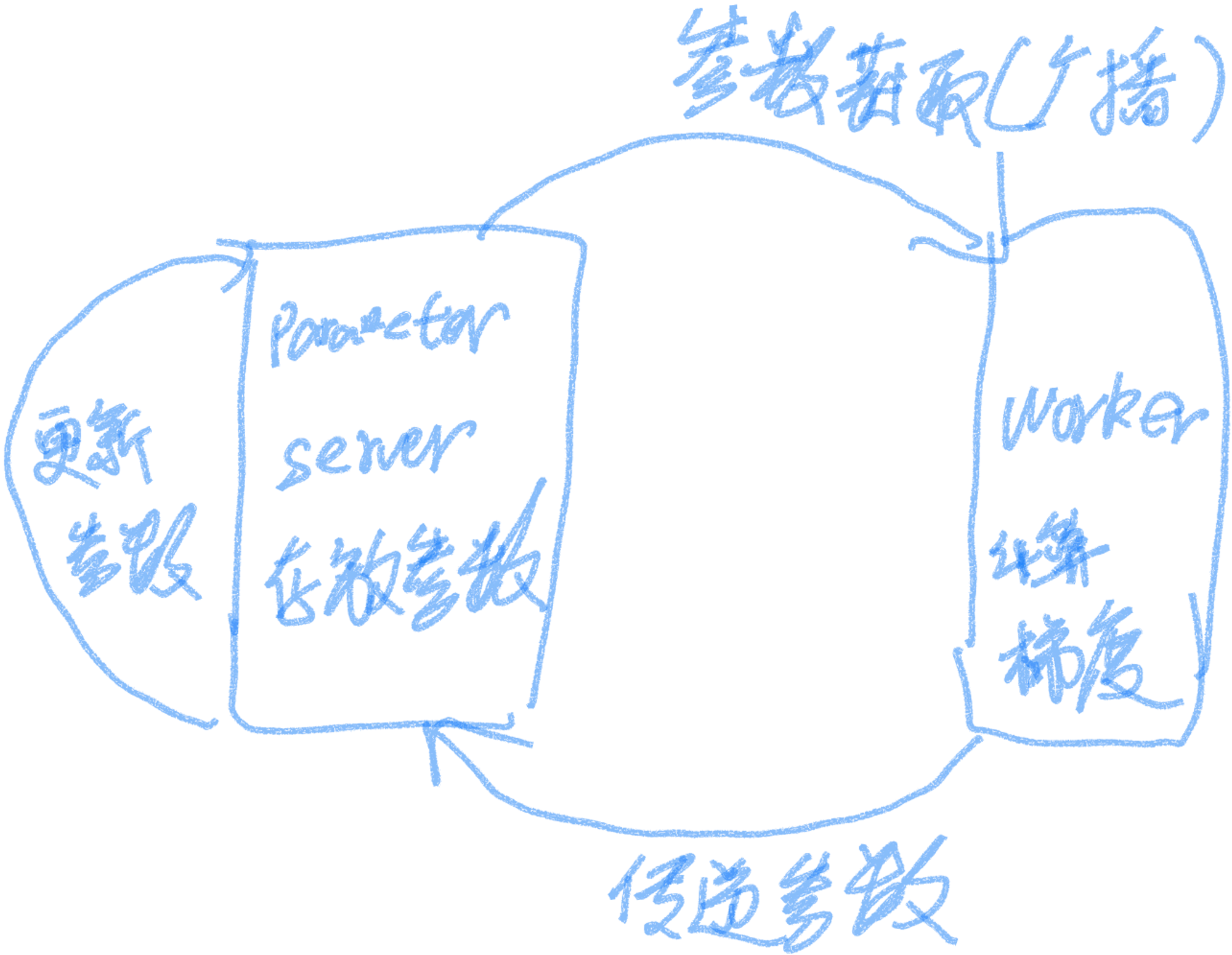
Parameter server
在这种架构中,集群中的节点被分为两类,parameter server和worker,前者用来存放模型参数,后者用来计算参数的梯度,在每个迭代过程,worker从parameter sever中获得参数,然后将计算的梯度返回给parameter server,parameter server聚合从worker传回的梯度,然后更新参数,并将新的参数广播给worker。(一般应该是一个ps对应多个worker)
每个计算节点在拿到新的batch数据之后,都要从参数服务器上取下最新的参数(应该是参数服务器广播出去吧?),然后计算梯度,再将梯度更新回参数服务器
Ring-allreduce架构
在Ring-allreduce架构中,各个设备都是worker,并且形成一个环,如下图所示,没有中心节点来聚合所有worker计算的梯度。在一个迭代过程,每个worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个worker,同时它也接收从上一个worker的梯度。对于一个包含N个worker的环,各个worker需要收到其它N-1个worker的梯度后就可以更新模型参数。其实这个过程需要两个部分:scatter-reduce和allgather,百度的教程对这个过程给出了详细的图文解释。百度开发了自己的allreduce框架,并将其用在了深度学习的分布式训练中。
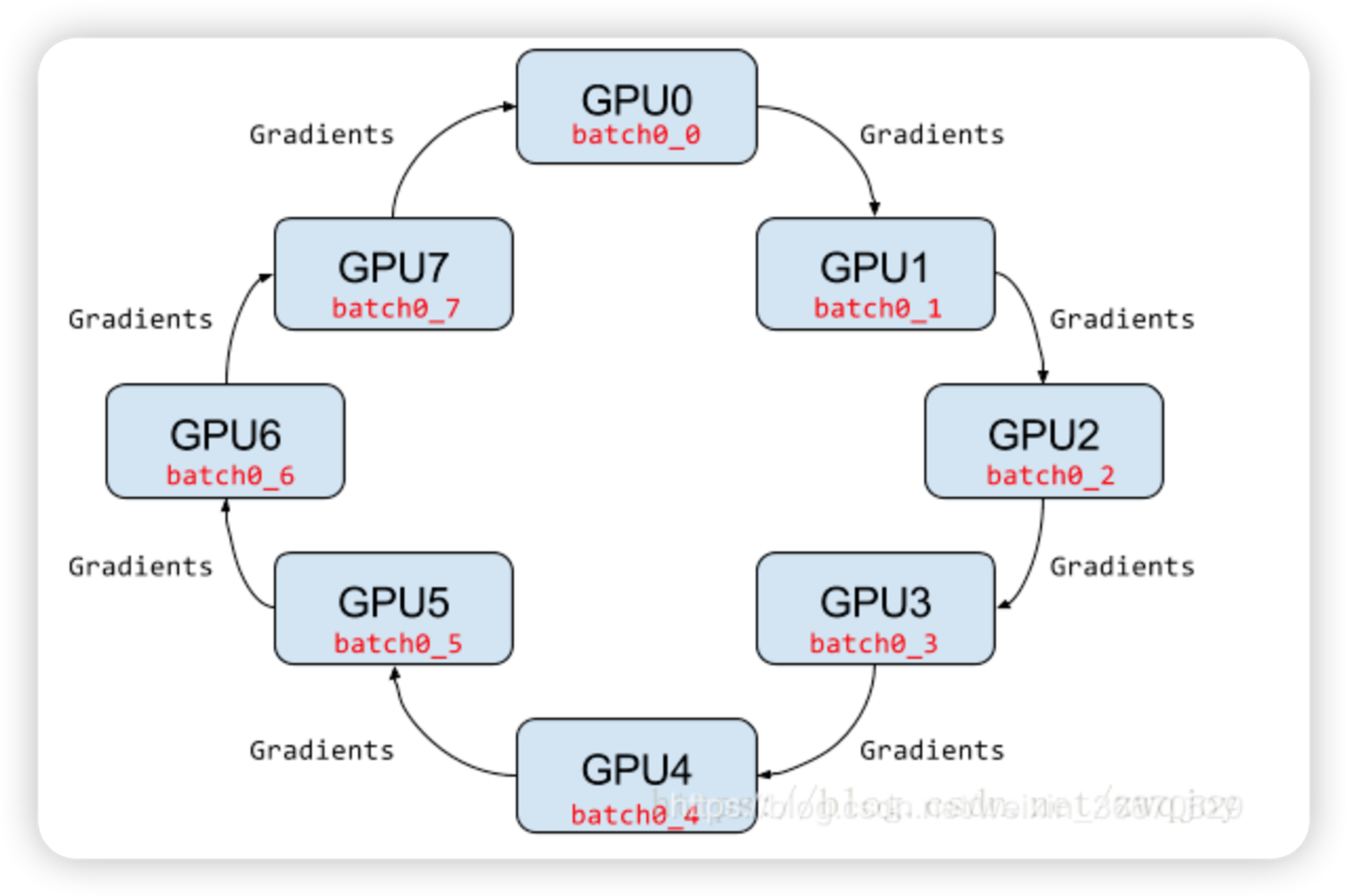
相比PS架构,Ring-allreduce架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用BP算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。在百度的实验中,他们发现训练速度基本上线性正比于GPUs数目(worker数)