GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE
date
icon
password
Sub-item
Blocked by
Parent item
type
status
slug
summary
tags
category
Blocking
乔治・霍兹(George Hotz)
GPT-4 是由 8 个混合专家模型组成的集成系统,每个专家模型都有 2200 亿个参数(比 GPT-3 的 1750 亿参数量略多一些),并且这些模型经过了针对不同数据和任务分布的训练。
信息 | 描述 |
模型架构 | ㅤ |
训练基础设施 | 针对不同数据和任务分布的训练 |
推理基础设施 | ㅤ |
参数数量 | 2200 亿个参数(比 GPT-3 的 1750 亿参数量略多一些) |
训练数据集 | ㅤ |
标记数量 | ㅤ |
层数 | ㅤ |
并行策略 | ㅤ |
多模态视觉适应 | ㅤ |
不同工程折衷的思考过程 | ㅤ |
独特实现的技术 | ㅤ |
如何缓解与推理巨型模型相关的最大瓶颈 | ㅤ |
最有趣的地方就是如何理解OpenAI为什么采用了这种架构
从GPT3到GPT4,OpenAI是想要scale到一百倍的,但是成本太高了。
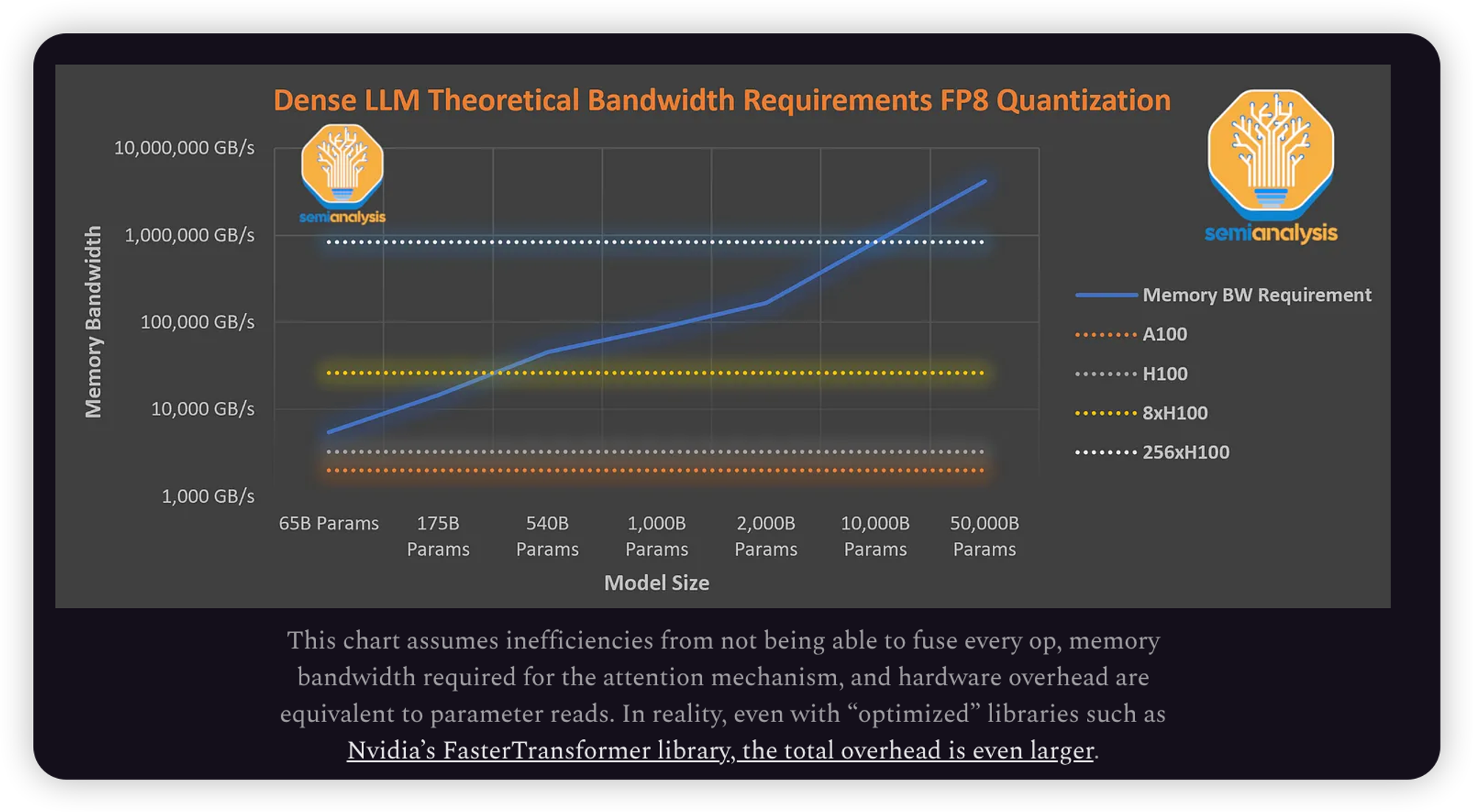
Dense transformers models will not scale further.
像OpenAI GPT-3, Google PaLM, Meta LLAMA, TII Falcon, MosaicML MPT这种Dense Transformer
这里其实没有看懂,为什么推理更重要,目前的情况是,没有任何一家公司做出了哪怕gpt3.5的水准吧
“扩展人工智能的一个更为重要的问题,也是真正的人工智能瓶颈,就是推理。目标是将训练计算与推理计算分离。这就是为什么在部署任何模型之前都有必要进行超过Chinchilla最佳状态的训练。这也是为什么需要使用稀疏模型架构;在推理过程中,并非每个参数都被激活。”